


Storage Spaces Direct (S2D) — программное решение Microsoft для построения отказоустойчивого, масштабируемого и высокопроизводительного хранилища на базе локальных дисков серверов. В связке с Failover Cluster оно позволяет объединять диски нескольких узлов в единый пул, предоставлять тома через CSV и SMB3 и обеспечивать автоматическое восстановление при отказах.
Ключевая идея и сценарии использования
— S2D объединяет локальные дисковые ресурсы серверов в единый пул хранения.
— Доступ к данным организован через Cluster Shared Volumes (CSV) и/или через Scale‑out File Server (SoFS) по SMB3.
— Подходит для виртуальных машин, баз данных, файловых шаров и гиперконвергентных инфраструктур.
Преимущества
— Отказоустойчивость: данные распределяются по узлам, потеря диска или узла не приводит к потере данных при корректной конфигурации.
— Масштабируемость: добавление узлов/дисков увеличивает ёмкость и IOPS.
— Производительность: использование NVMe/SSD для кеша и распределённая обработка I/O снижает задержки.
— Экономия: можно использовать стандартное серверное железо вместо дорогих SAN.

Ограничения и ключевые требования
1. Минимум узлов: — 2 (для простейших сценариев), рекомендуется 3 и более для стабильности.
2. Максимум узлов: — 16 в одном кластере (стандартное ограничение для S2D).
3. Аппаратная совместимость: серверы, диски, сетевые адаптеры и прошивки должны быть сертифицированы для S2D.
4. Сеть: — минимум 10 Гбит, поддержка SMB Multichannel и желательно RDMA (RoCE / iWARP) для лучшей производительности.
5. Диски: — используются в режиме JBOD (не RAID с агрегированным контроллером).
6. Файловая система: — рекомендуется ReFS для томов S2D (CSVFS_REFS).

Архитектура: варианты развёртывания
— Гиперконвергентный (HCI): вычисления и хранилище на тех же узлах — экономичный и простой в масштабировании вариант.
— Конвергентный: отдельные серверы для хранения и отдельные для вычислений — даёт гибкость в выделении ресурсов.
Подготовка: перед развёртыванием
— Планирование: определите требования по ёмкости, IOPS, ожидаемым отказам и RPO/RTO.
— Сертификация железа: используйте поддерживаемые модели серверов, контроллеров и дисков.
— Сеть: спроектируйте отдельные каналы для управления, кластерного трафика и Storage‑трафика; обеспечьте резервирование.
— Образы ОС: предпочтительна минимальная установка Windows Server (Server Core допускается).

Базовый пошаговый план развёртывания (PowerShell)
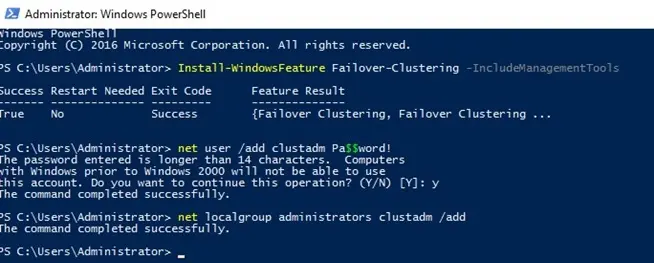
1. Установка роли Failover Clustering и инструментов:
Install-WindowsFeature -Name Failover-Clustering -IncludeManagementTools
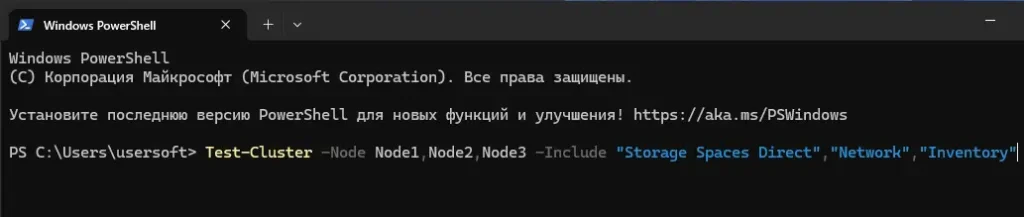
2. Валидация конфигурации (важно перед созданием кластера):
Test-Cluster -Node Node1,Node2,Node3 -Include "Storage Spaces Direct","Network","Inventory"
— Исправьте все критические ошибки, выявленные тестом.
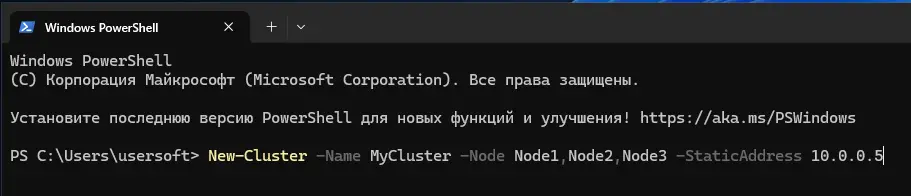
3. Создание кластера:
New-Cluster -Name MyCluster -Node Node1,Node2,Node3 -StaticAddress 10.0.0.5
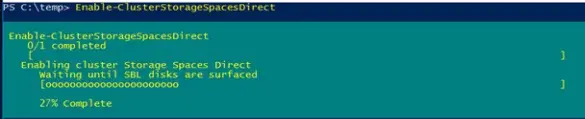
4. Включение Storage Spaces Direct:
Enable-ClusterStorageSpacesDirect
— Команда создаёт пул хранения из доступных дисков и настраивает необходимые службы.
5. Создание тома и добавление в CSV (рекомендуется ReFS):
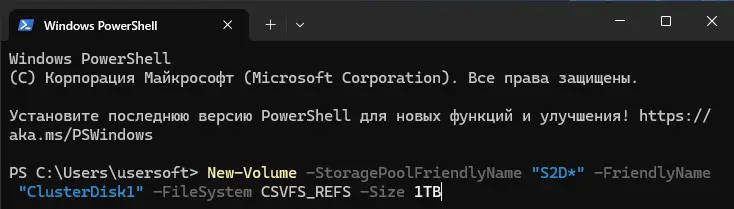
New-Volume -StoragePoolFriendlyName "S2D*" -FriendlyName "ClusterDisk1" -FileSystem CSVFS_REFS -Size 1TB
6. Настройка Scale‑out File Server и шаров (если нужен доступ по SMB):
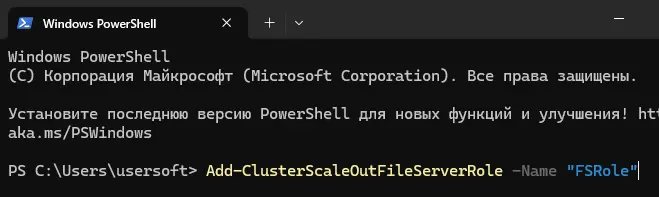
Add-ClusterScaleOutFileServerRole -Name "FSRole"
— Создайте SMB‑шары на CSV и настройте разрешения.
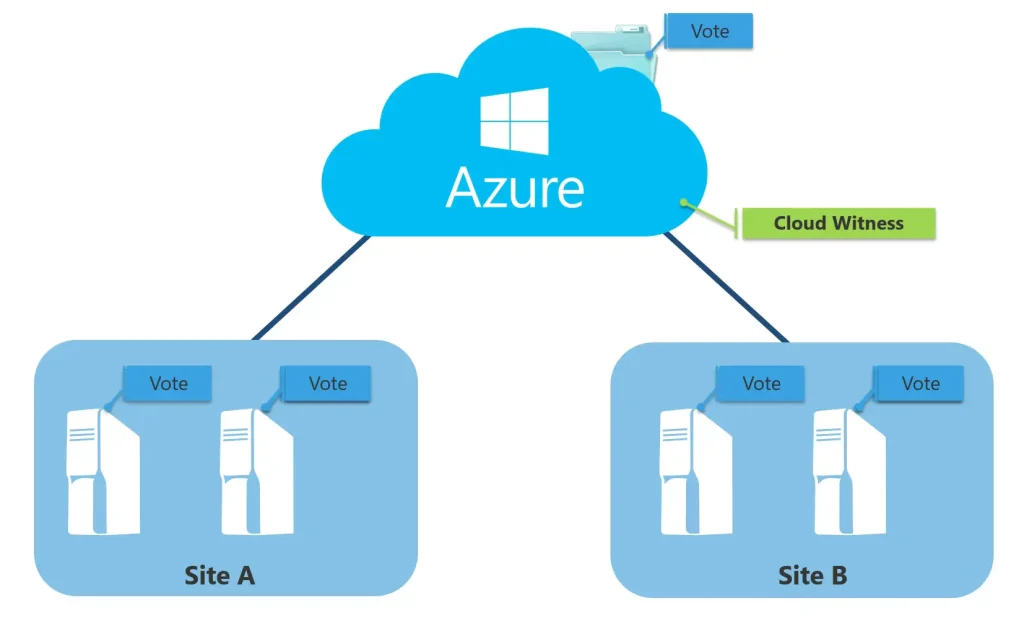
Вопросы кворума и witness
— Для небольших конфигураций используйте File Share Witness или Cloud Witness (Azure) для обеспечения кворума.
— При нечётном числе узлов кворум проще и надёжнее; при чётном числе обеспечьте внешний witness.
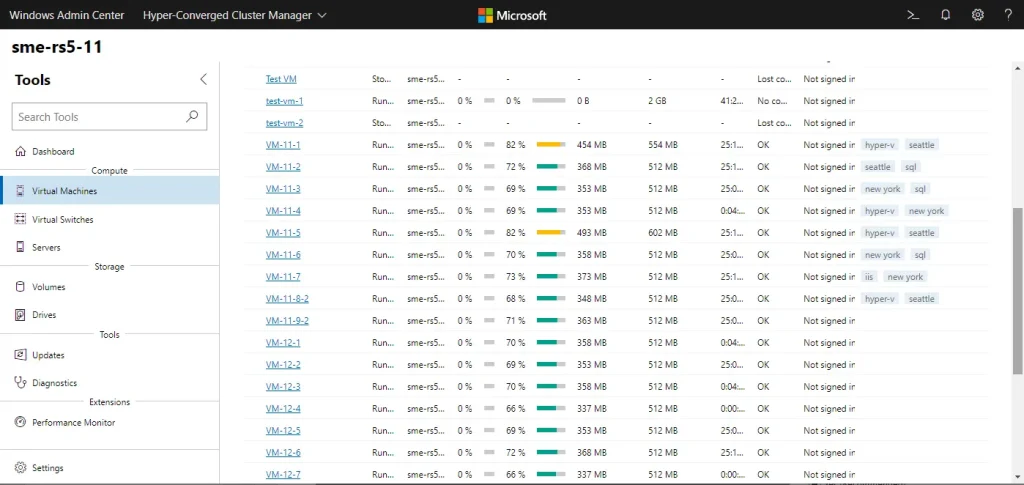
Мониторинг, обслуживание и обновление
— Используйте Windows Admin Center и инструменты Failover Cluster Manager для мониторинга здоровья кластера и пулов S2D.
— Планируйте rolling upgrades при обновлении прошивок/ОС, чтобы избежать простоев.
— Следите за состоянием дисков и восстановлением данных (rebuild): операции реконструкции могут снижать производительность.
Лучшие практики
— Всегда начинать с тестовой среды и прогнать сценарии отказа.
— Не смешивайте в одном пуле несопоставимые модели дисков без понимания влияния на политику кеширования.
— Проектируйте сеть с изоляцией трафика: management, cluster, storage.
— Планируйте резервирование: RAID на контроллерах не рекомендуется — S2D управляет избыточностью.

Типичные проблемы и как их решать
— Failover не инициируется: проверьте сетевые интерфейсы, настройки кворума и состояние Node Health.
— Долгая реконструкция: проверьте нагрузку I/O, скорость дисков и возможность временно снизить приоритет rebuild.
— Неподдерживаемое оборудование: приведите драйверы/прошивки к поддерживаемым версиям или замените компоненты.
Storage Spaces Direct с кластеризацией — эффективный инструмент для создания отказоустойчивого и масштабируемого хранилища на стандартном серверном железе. При грамотном планировании, использовании сертифицированного оборудования и корректном мониторинге S2D может заменить дорогие SAN-решения и обеспечить требуемый уровень RTO/RPO для большинства нагрузок.